
Hi, In this article we will see a complete guide on How to to read CSV file into Pandas DataFrame with the help of the proper example. If you are working as a data engineer, data analyst, or data scientist you must have knowledge about this because, in the end, you have to deal with datasets.
In the data field, CSV is one of the most used file formats in order to store large volumes of data in this article we will explore how we can read data from CSV files into Pandas dataframe.
As we know, In Python, Pandas is one of the most popular and widely used libraries for data analysis. Pandas provides tons of methods and properties in order to deal with data.
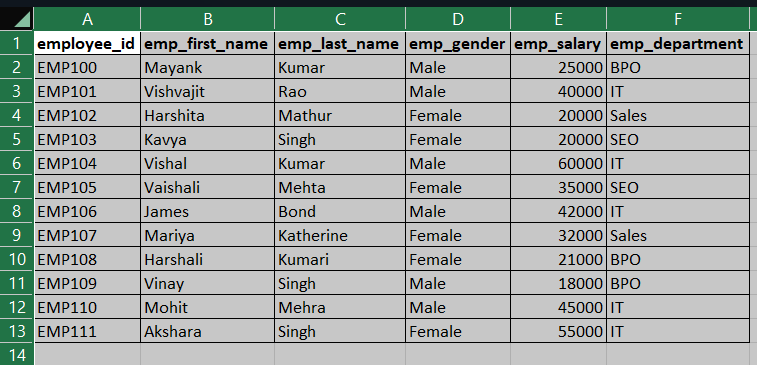
For the demonstration of this article, I have prepared a sample dataset as you can see in the below screenshot but in real-life applications, you will deal with large amounts of datasets.
To read data from CSV file, Pandas provide a method called read_csv() and the read_csv() method accepts various parameters that can be used according to data and requirement.
Let’s explain the Python Pandas read_csv() method to read data from CSV files along with different parameters.
Here I am using Jupyter Notebook to write the code but you can use any code editor as per your wish because the code will be the same in all code editors.
Headings of Contents
- 1 Read CSV File into Pandas DataFrame
- 2 Read CSV file into Pandas DataFrame with Pipe Delimiter
- 3 Read Specific Column from CSV file into Pandas DataFrame
- 4 Read CSV file into Pandas DataFrame with Different Column Names
- 5 Read CSV file into Pandas DataFrame with Different Index
- 6 Read a Specific Number of Rows from CSV
- 7 Skip Lines Number from the start of the CSV file
- 8 Skip Lines Number from the Bottom of the CSV file
- 9 Conclusion
Read CSV File into Pandas DataFrame
In the CSV file, all the items have been separated by commas delimiter which is the default value of the delimiter parameter in the read_csv() method. Most of the time items in the CSV file are separated through a comma (,) that’s it’s the default value of the delimiter parameter of the read_csv() method. Here I am not going to pass any extra parameters except the path of the CSV file to the read_csv() method because, for a standard CSV file, it already comes with a default value.
Below is the basic code to read CSV file into Pandas DataFrame.
import pandas as pd
df = pd.read_csv('../../Datasets/employee_dataset.csv')
print(df) 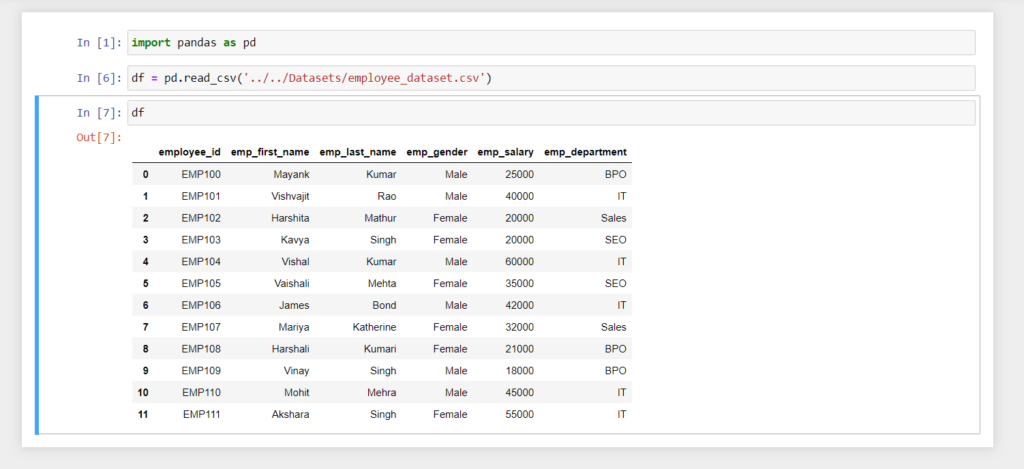
Read CSV file into Pandas DataFrame with Pipe Delimiter
Sometimes items of the CSV file have been separated by pipe delimiter ( | ), In that particular scenario we have to pass the pipe ( | ) symbol to the delimiter parameter of the read_csv() method.
import pandas as pd
df = pd.read_csv('../../Datasets/employee_dataset.csv', delimiter='|')
print(df)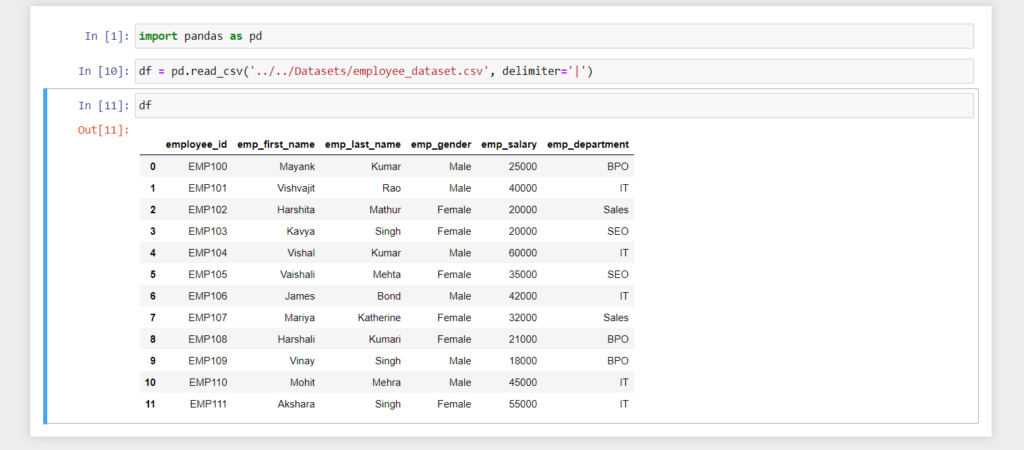
Read Specific Column from CSV file into Pandas DataFrame
It might be, that CSV files have various columns but most of the time we want to perform operations on some specific columns so it does not make sense to load all the unwanted columns into Pandas DatFrame.Pandas read_csv() method has a parameter called usecols which accepts column names as a list to be loaded.
For example, I want to read only the ‘employee_id‘, ‘emp_first_name‘, ‘emp_last_name‘, and ‘emp_salary‘ columns into Pandas DataFrame then I will pass this column as a list into usecols parameter.
import pandas as pd
df = pd.read_csv(
'../../Datasets/employee_dataset.csv',
usecols=['employee_id', 'emp_first_name', 'emp_last_name', 'emp_salary']
)
print(df)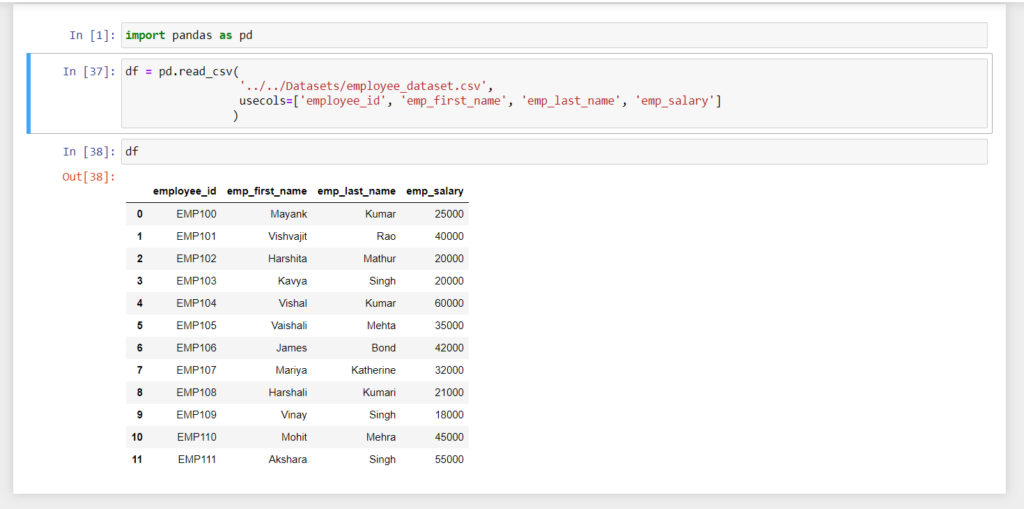
Read CSV file into Pandas DataFrame with Different Column Names
Sometimes we don’t want to use column names specified in the CSV file instead of those columns we want to use different column names then we can use the names parameter of the read_csv() method.
For example, I want to use column names [‘Employee Id’, ‘First Name’, ‘Last Name’, ‘Gender’, ‘Salary’, ‘Department’] instead of column names [’employee_id’, ’emp_first_name’, ’emp_last_name’, ’emp_gender’, ’emp_salary’, ’emp_department’].
Note:- if your file has head row or column names as the first row then you must have to pass the header=0 to the read_csv() method to override the first row of the file.
import pandas as pd
df = pd.read_csv(
'../../Datasets/employee_dataset.csv',
header=0,
names=['Employee Id', 'First Name', 'Last Name', 'Gender', 'Salary', 'Department']
)
print(df)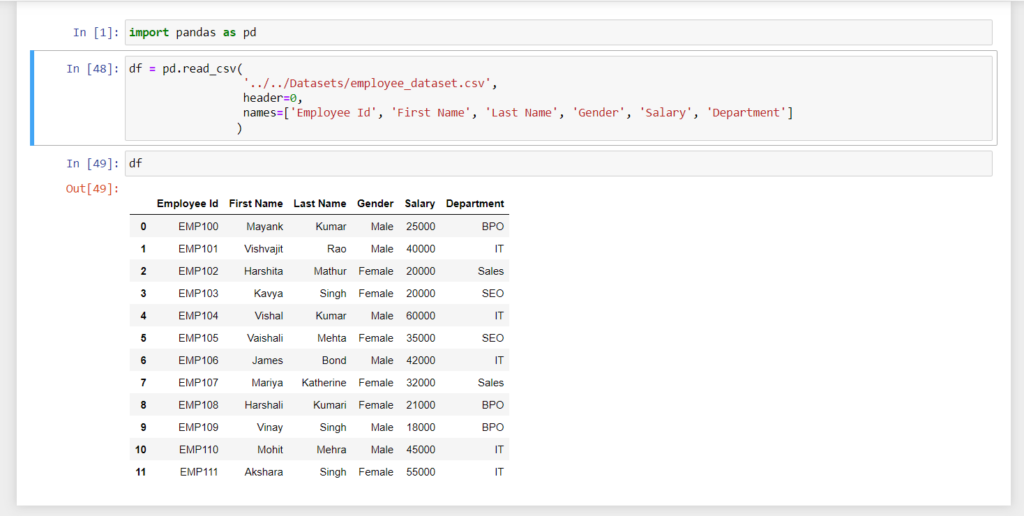
Read CSV file into Pandas DataFrame with Different Index
As you can see in all of the above DataFrame, An index column has returned which is started from 0 to a total number of rows minus 1, Row labels always start from zero by default but in some scenarios, we want to change it with our own row label indexes.
In that situation, we can use the index_col parameter of the read_csv() method.
Here I am about to use the employee_id column as an index of the DataFrame.
import pandas as pd
df = pd.read_csv(
'../../Datasets/employee_dataset.csv',
index_col=['employee_id']
)
print(df)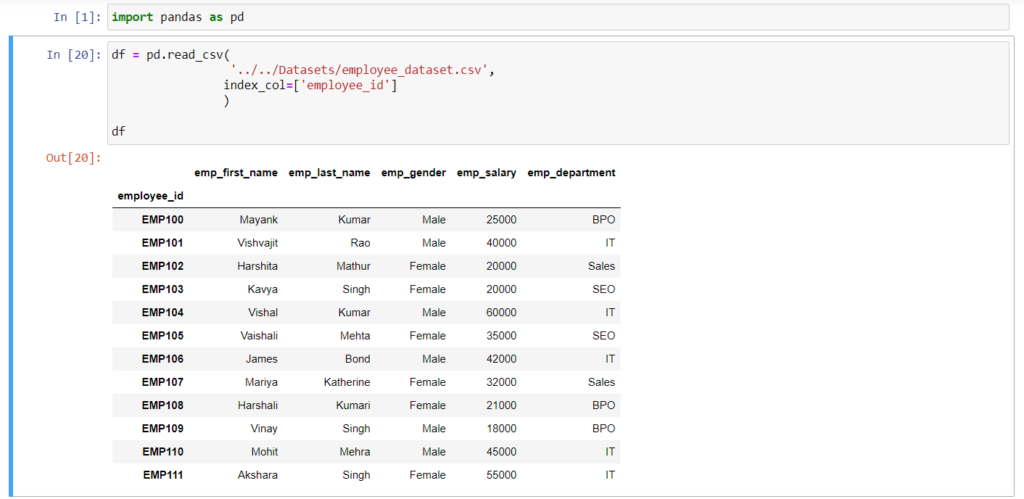
As you can see, employee_id has been successfully assigned as an index of the DataFrame.
Read a Specific Number of Rows from CSV
To read a specific number of rows from a CSV file, we can use nrows parameter. nrows parameter is very useful especially when we work on large CSV files because sometimes we want to load some rows from CSV as samples to perform some operations.
For example, Here I am going to read only 5 rows from the CSV file.
import pandas as pd
df = pd.read_csv(
'../../Datasets/employee_dataset.csv',
nrows=5
)
print(df)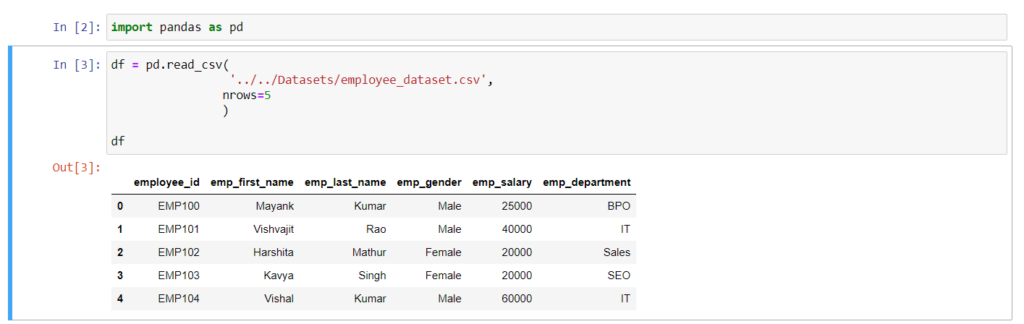
Skip Lines Number from the start of the CSV file
The read_csv() method has a parameter called skiprows that is used to skip the specific line or number of lines to skip from the start of the file.
Example:- Skip the first 5 lines from the CSV file
# Skip total five lines from the csv file
import pandas as pd
df = pd.read_csv(
'../../Datasets/employee_dataset.csv',
skiprows=5
)
print(df)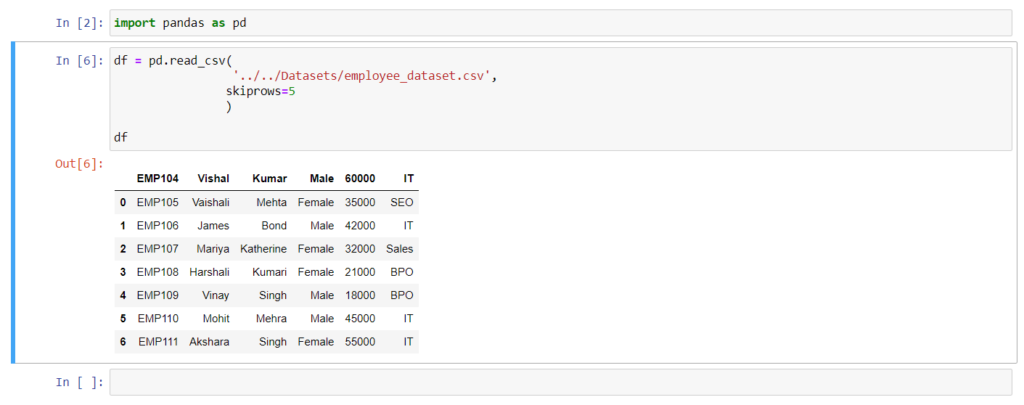
Example:- Skip the first and second lines from the CSV file
# Skip first and second line from the csv file
import pandas as pd
df = pd.read_csv(
'../../Datasets/employee_dataset.csv',
skiprows=[0, 1]
)
print(df)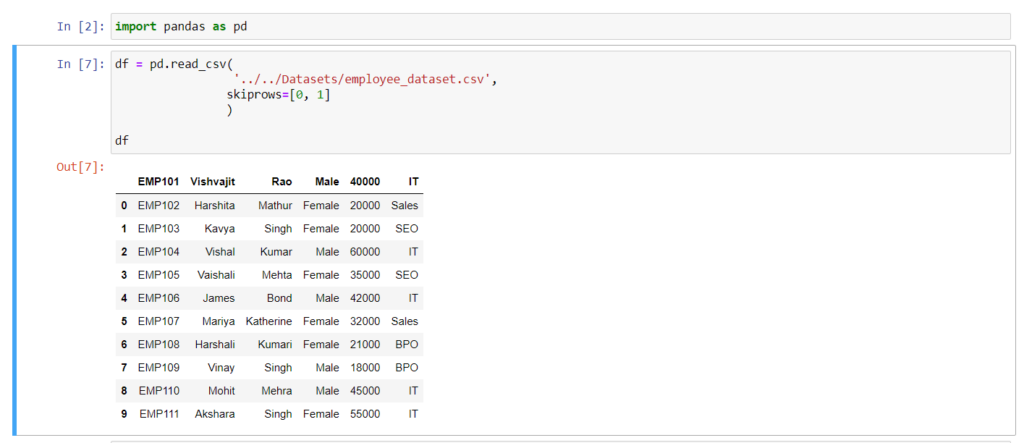
Skip Lines Number from the Bottom of the CSV file
read_csv() method has a parameter called skipfooter that is used to skip a specific number of lines from the bottom of the file. You will get a warning message if you will use skipfooter parameter, To about that parameter you can use engine=’python’ in the read_csv() method.
Here I am skipping 5 lines from the bottom of the file.
import pandas as pd
df = pd.read_csv(
'../../Datasets/employee_dataset.csv',
skipfooter=5
engine='python'
)
print(df)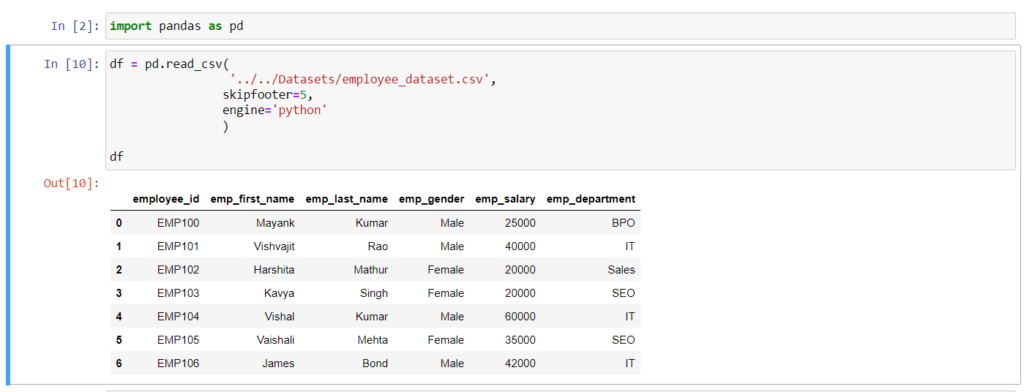
These are some popular ways to read CSV file into Pandas DataFrame which you can use. Apart from this parameter, the read_csv() method accepts various methods that you can use based on your requirements.
Conclusion
In this article, we have seen a complete tutorial to read CSV file into Pandas DataFrame with the help of various examples. Pandas read_csv() method accepts various parameters which can be used for a specific purpose.
If you can use any parameter based on the nature of data and also based on your requirement. Apart from CSV files, you can also read data from various source systems into Pandas DataFrame which can be discussed in upcoming Pandas tutorials.
If you found this tutorial helpful, please share and keep visiting for further Pandas tutorials.
Thanks for visiting.
Official Pandas read_csv() method Documentation:- Click Here





