
Hi there, In this article, you will learn everything about how to create an AWS S3 bucket using the AWS management console, AWS CLI ( Command Line Interface), and Python program. You can use any one of them in order to create your S3 bucket at your convenience.
Basically, AWS S3 ( Simple Storage Service ) is a storage service offered by AWS (Amazon Web Services) in order to store objects like structure and unstructured data and access them from anywhere.
Before going to create an AWS S3 bucket, we will see a little bit about AWS S3, S3 bucket, Key, etc.
Headings of Contents
- 1 What is AWS S3 ( Simple Storage Service )?
- 2 What is AWS S3 Bucket?
- 3 AWS S3 Bucket Name Examples
- 4 How does AWS S3 ( Simple Storage Service ) Work?
- 5 Step-by-Step Guide to Create New AWS S3 Bucket
- 6 Create AWS S3 Bucket using AWS CLI ( Command Line Interface )
- 7 Creating AWS S3 Bucket using Python Boto3
- 8 Created AWS S3 Buckets
- 9 Uploading Objects in Bucket
- 10 Conclusion
What is AWS S3 ( Simple Storage Service )?
S3 means Simple Storage Service offered by AWS ( Amazon Web Services ). It is an object storage service that offers industry-leading scalability, security, and high availability.
Customers of all sizes can store and protect their data for long-term use cases like mobile applications, websites, data lakes, backup and restore, enterprise applications, IoT Devices, Big Data Analytics, etc.
AWS S3 provides full management features so that you can store, optimize and configure access to your data that meets specific businesses, organizations, etc.
What is AWS S3 Bucket?
In AWS S3, Bucket is just a container that is used to store objects, without a bucket we can’t store anything in AWS S3 that’s why it is super important. You can store any number of objects inside a bucket and only 100 buckets can exist in an AWS account.
When you create a bucket in AWS S3, you provide the name of the bucket and choose the region where you want to store the objects. Once one bucket has been created you can not change the name of the bucket and region. Bucket names must be satisfied the condition of bucket naming rules.
Bucket Naming Rules:
The following rules must be applied in order to create a new bucket in AWS S3.
- The bucket name must be between 3 (min) and 64 (max) long characters.
- The bucket name can consist only of lowercase letters, hyphens(-), dots(.), and numbers.
- The bucket name must begin and end with letters or numbers.
- The bucket name must not contain two adjacent periods.
- The bucket name must not be performed as an IP address.
- The bucket name must not start with the prefix xn--.
- The bucket name must not end with the suffix -s3alias.
- The bucket name must be unique across all AWS accounts in all AWS regions.
- A Bucket name cannot be used with another AWS account in the same partition until it gets deleted.
So these are a few important rules in order to create a new AWS S3 bucket and your bucket must be followed these rules.
👉 AWS S3 Bucket Naming Rules:- Click Here
AWS S3 Bucket Name Examples
Here, I have provided some valid and invalid AWS S3 bucket names.
Valid AWS S3 Bucket Names:
- students-data-2023 -> It is a valid bucket name because it has contained hyphens and lowercase characters and numbers.
- company-employee-data -> It is a valid bucket name because it contains hyphens and lowercase characters.
In Valid AWS S3 Bucket Names:
- students_data_2023 -> Not valid because it contained an underscore which is not allowed in bucket name.
- Company-Employee-Data -> Not valid because it has contained Upper Case characters.
How does AWS S3 ( Simple Storage Service ) Work?
As we know, Amazon S3 is an object storage service that is used to store data as an object within a bucket. An object is a file and any metadata that is capable of describing information about the data. It is a kind of container for an object.
To store objects in an S3 bucket, first of all, we have to create an S3 bucket by specifying the bucket name and AWS region. Then we upload data to the created bucket as an object.
Each object has a key that is responsible for identifying each object in the bucket uniquely. AWS S3 provides multiple configurations that you can use while you create an S3 bucket name.
It is a very versatile cloud storage system along with many features. I have mentioned some important S3 ( Simple Storage System ) terminologies that you should have knowledge of.
Objects
Objects are nothing but data stored in an S3 bucket. Objects consist of object data and metadata. The metadata is key-value pairs that represent the object in the S3 bucket.
These pairs include some default metadata of the objects like the last modified date and standard HTTP metadata such as Content-Type. You can also store your own custom metadata during the object is stored. An object is uniquely identified by a key name and version id.
Keys
An object key is the same as a key name that is used to uniquely identify each object within a bucket. Every object within the bucket has exactly one unique key.
Every object in the Amazon S3 bucket can be uniquely addressed through a web service endpoint like bucket name, key, optionally, and version id. For example, in the URL https://employee-data.s3.us-west-2.amazonaws.com/employee/employee_one.csv, employee-data represents the bucket name and employee/employee_one.csv represents the key name.
S3 Versioning
S3 versioning is a way of keeping the multiple variants of the object in the same bucket. With the help of S3 versioning, You can preserve, restore and retrieve every version of the objects stored in your buckets. You can easily recover from both unintended user actions and application failure.
Version ID
When you enable the version id in the S3 bucket, Amazon S3 generates a unique id for each object stored in the bucket. Objects that already exist in the bucket at the time enable that will have a version if null. Next time when you will update that object, Amazon s3 will generate a unique id for them.
Region
The region in AWS S3 represents the geographical location where your bucket will be created. You must have to choose the region during the creation of the AWS S3 bucket.
Now let’s see how can we create a new S3 bucket, Throughout this article we will see a total of three ways to create a new S3 bucket.
- Using AWS Management Console.
- Using AWS CLI ( Command Line Interface ).
- Using Python boto3 library.
Step-by-Step Guide to Create New AWS S3 Bucket
There are three ways available in order to create a new AWS S3 bucket. You can opt for any one of them at your convenience. I am assuming, You have created an AWS account and you have created an AWS IAM user also.
If you still don’t have an AWS free tier account and IAM user, Then you can follow the below link in order to create a new AWS free tier account for 12 months and AWS IAM user as well.
Creating AWS S3 Bucket using Management Console:
If you have AWS IAM user credentials that have permission to login into AS Management console and S3 full access policy, you can easily create a new S3 bucket. Please follow all the steps that I have mentioned underneath to create a new bucket.
- Login into the AWS Management console through IAM user credentials Search for S3 in the search box and click on S3.
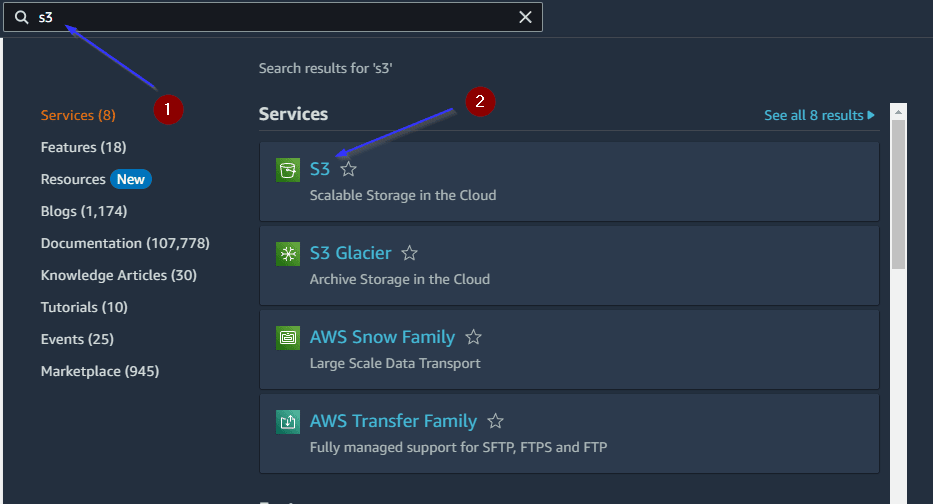
- Click on Create bucket after clicking on the Buckets button on the left side.
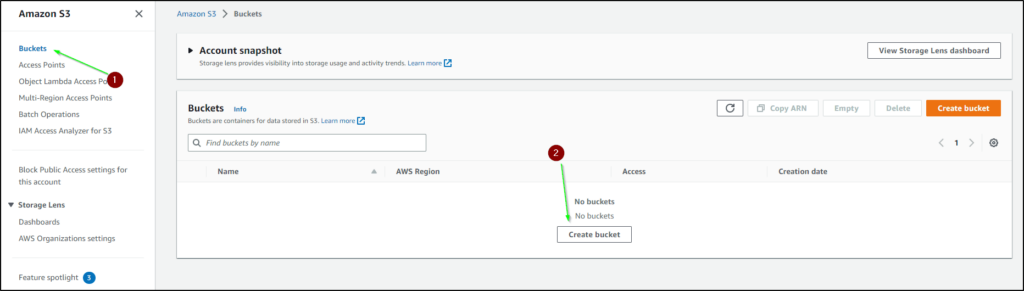
- After clicking on Create bucket, you will see a window where multiple sections will be included.
- In the General Configuration, provide the name of the bucket make sure your bucket name satisfied the above bucket naming rules, and also choose the region where you want to create your bucket.
- In the Object Ownership section, Leave it by default.
- In Block Public Access settings for this bucket, Leave all the settings by default. If you will enable this, Then all the objects within this bucket can be accessed publicly, If you want to store sensitive data then always go with the default setting.
- Leave all the settings in the Bucket versioning section default.
- You can provide a tag for this bucket otherwise you can leave it because it is completely optional.
- Leave all the settings of Default encryption and Advanced settings as it is.
- It will take a few seconds to create a new S3 bucket and after that, you will see a successful message.
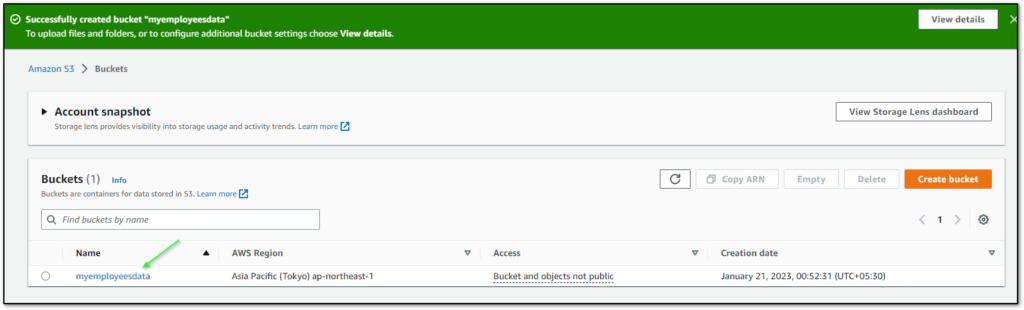
Note:- myemployeesdata is the name of the S3 bucket in my case it will different in your case.
This is how you can create an AWS S3 bucket using AWS Management Console.
Now let’s see a second way to create a new s3 bucket using AWS CLI ( Command Line Interface ).
Create AWS S3 Bucket using AWS CLI ( Command Line Interface )
Before using this AWS CLI, AWS CLI must be configured in our system. Without configuring AWS CLI ( Command Line Interface ) you can’t use AWS CLI to make requests for AWS services.
I have written a detailed article about how to install and configure AWS CLI on Windows machines.
You can click on the below link to read that article.
👉Install and Configure AWS CLI in Windows
Now, I am assuming, You have successfully installed and configured AWS CLI on your machine.
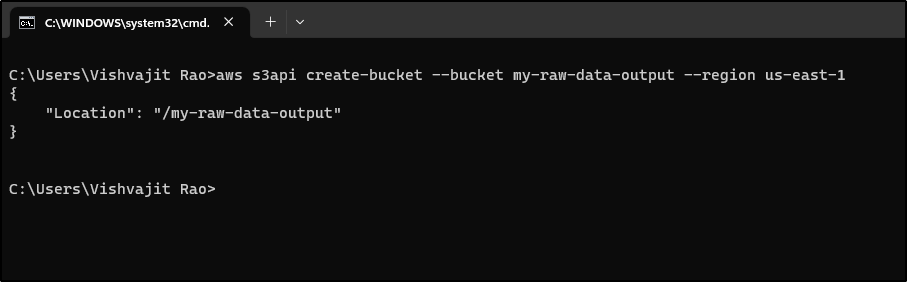
Just open your window command prompt and type the below command in order to create a new AWS S3 bucket. I have mentioned the bucket name and region name where I want to create my bucket, There are multiple parameters available that you can pass as a parameter.
As we have seen earlier in the process of creating an AWS S3 bucket using the AWS management console, We had multiple settings during the creation of the bucket name. You can pass all of those settings as a parameter using the AWS CLI s3api command.
aws s3api create-bucket --bucket my-raw-data-output --region us-east-1
You can explore more about the AWS CLI s3api command by clicking here.
Creating AWS S3 Bucket using Python Boto3
Boto3 is nothing but a library just like a normal library in Python. It is used to make requests for AWS services through Python programming. Using the Boto3 library, We can manage AWS services through Python code.
As Python developers, we must have knowledge about how we can use Python boto3 library in order to make requests for AWS services.
Make sure you have downloaded the boto3 Python library through the below command.
pip install boto3If you are using Anaconda, then you can this command in order to install Boto3.
conda install boto3To use Boto3, You have to be configured the AWS IAM user access key and secret key in your machine or system.
You can click on the below link to know how to configure the AWS IAM user access key and secret key for AWS CLI ( Command Line Interface ) and Boto3 library.
👉 Configure the AWS IM access key and secret key in the local machine
If you didn’t configure the access key and secret key in your machine but have created AWS IAM user credentials for programmatic requests. Then you can explicitly pass the access key and secret key in boto3.client() method.
boto3.client("s3", access_key="Your access key", secret_key="You secret key")
👉 Step by Step Guide to Create AWS IAM User
But I have configured the access key and secret key in my machine that’s why I don’t need to pass the access key and secret key in boto3.client() method.
Simple Python script to create an S3 bucket using Boto3 Library.
import boto3
# creating client
client = boto3.client("s3")
# creating bucket
response = client.create_bucket(
Bucket="my-raw-input-data",
CreateBucketConfiguration={
'LocationConstraint': 'us-east-2',
}
)
# BucketAlreadyExists:
print(response)
Output
{'Location': 'http://my-raw-input-data.s3.amazonaws.com/',
'ResponseMetadata': {'HTTPHeaders': {'content-length': '0',
'date': 'Sat, 18 Feb 2023 19:11:47 GMT',
'location': 'http://my-raw-input-data.s3.amazonaws.com/',
'server': 'AmazonS3',
'x-amz-id-2': 'mqmgtQ3hTCPLjg2GgjXYErrxAeXEoVasHRBAFLb/XJSed+zM0t25B5bM4NeZw8XsWZ9SkjMETVE=',
'x-amz-request-id': 'ZZKBHG5GQ9Y1YJV9'},
'HTTPStatusCode': 200,
'HostId': 'mqmgtQ3hTCPLjg2GgjXYErrxAeXEoVasHRBAFLb/XJSed+zM0t25B5bM4NeZw8XsWZ9SkjMETVE=',
'RequestId': 'ZZKBHG5GQ9Y1YJV9',
'RetryAttempts': 0}}
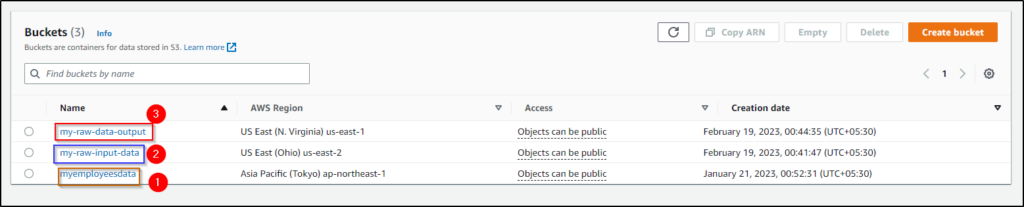
Created AWS S3 Buckets
Throughout this article, we have created three AWS S3 buckets called myemployeesdata, my-raw-input-data, and my-raw-data-output. As you can see in My AWS Management console, all of the buckets have been shown successfully.
Now let’s see the process of uploading objects inside an S3 bucket.
Uploading Objects in Bucket
So far we have seen the process of creating an AWS S3 bucket using the AWS Management Console, AWS CLI, and Python Boto3 library. Now, We will see how to upload objects in a Bucket.
- To upload objects, Just click on the Bucket name where you want to upload your objects.
- Click on the Upload button.
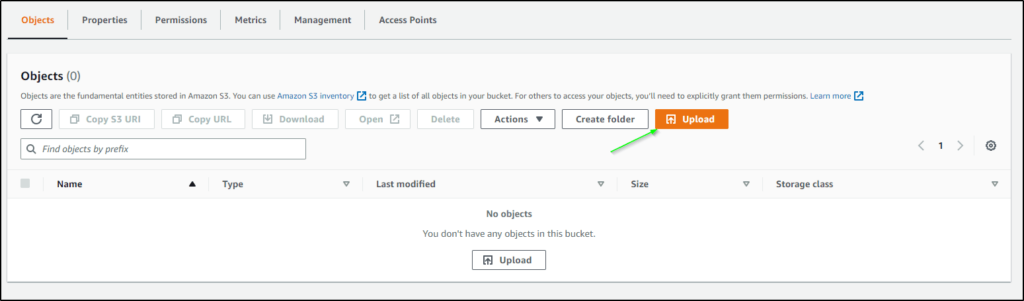
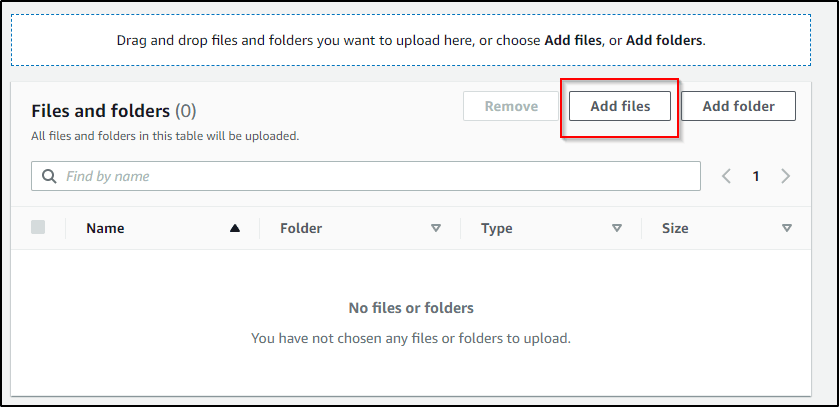
- Click on Add files, You can also add a folder in your Bucket but I am about to upload files only.
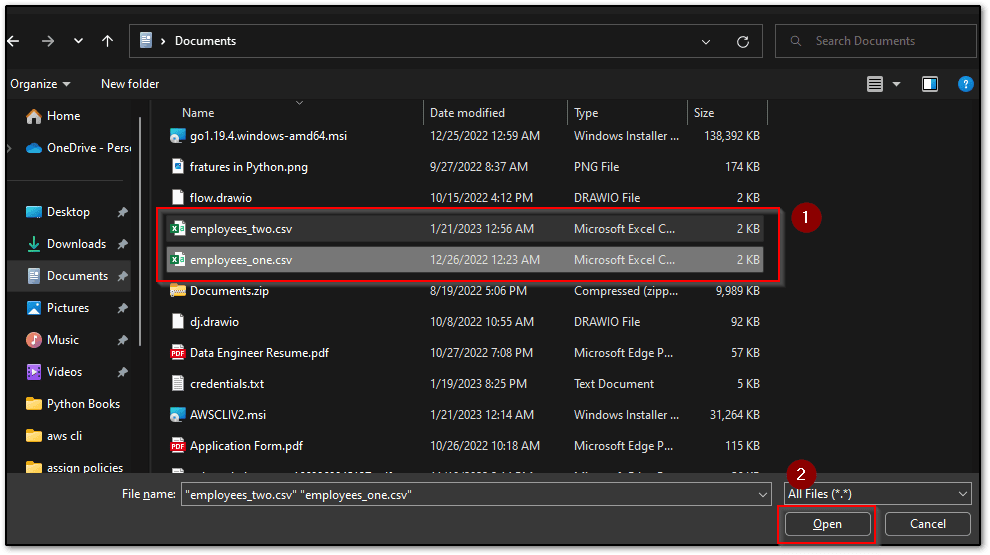
- Choose files that you want to upload to your bucket from the system and click on Open.
- Now, you will see all the files that you have selected for uploading will be showing in the Files and Folders section if everything is ok, Then click on the Upload button.
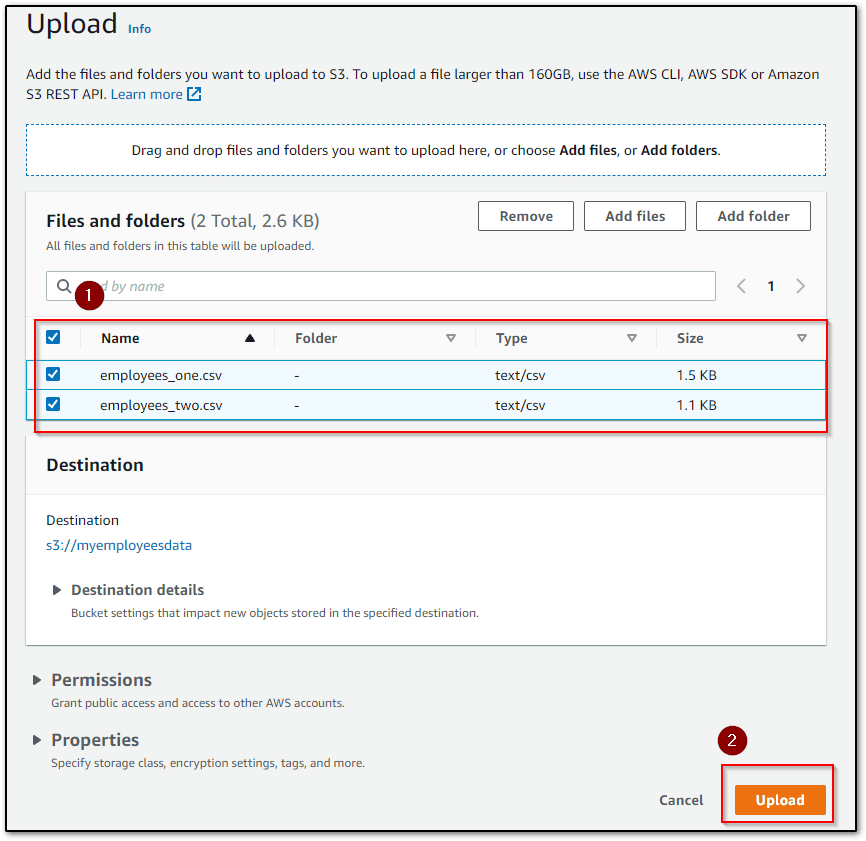
Now, Your files will be uploaded successfully in your selected bucket as you can see in my case, All the files that I had selected have been uploaded to the bucket.
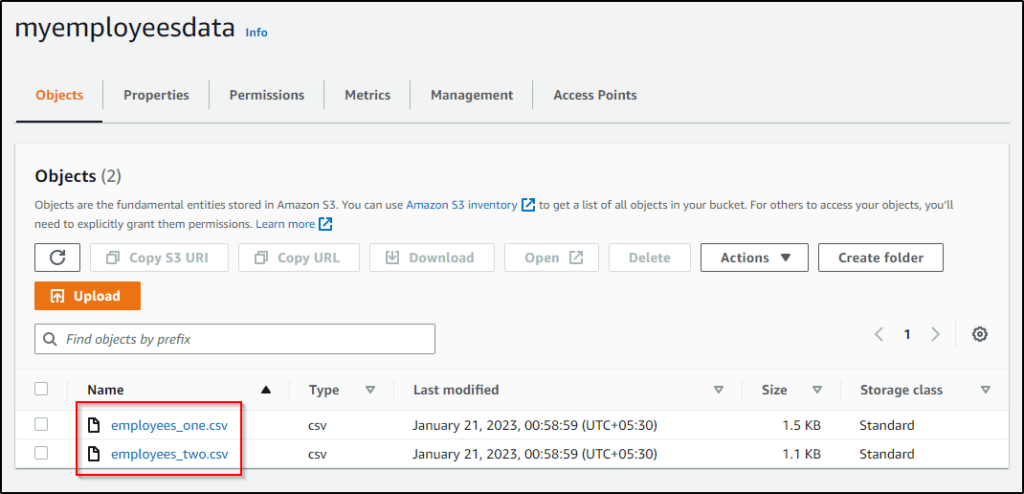
This is how you can upload objects or data inside the AWS S3 bucket.
Conclusion
I hope the process of creating an AWS S3 bucket using AS Management console, AWS CLI, and Python Boto3 was easy and straightforward. You can go with any method in order to create a new ASW S3 bucket to store data. Data could be structured or unstructured.
AWS S3 is one of the widely used AWS services, As a Developer, Data Engineer, Data Analyst, AWS Cloud engineer, etc you must have knowledge of AWS S3 because nowadays every data is being shifted to the cloud. Most companies are being shifted their data to AWS S3 bucket because it’s more scalable, secure, and makes highly available.
I hope you found this article helpful, Please share and keep visiting for further AWS tutorials.
If you have any queries please mail us at the mail id mentioned on the contact page.
Thanks for your valuable time…
Have a nice day.





