
In this article, you will learn all about how to write PySpark DataFrame to CSV with the help of the examples. PySpark provides a class called DataFrameWriter that has various methods in order to write PySpark DataFrame to different-different target systems like flat files, Databases, S3 storage, key-value, etc.
This tutorial is going to be very helpful because CSV is one of the most popular file formats in order to store data in plain text format and it is being used mostly in the data field, That’s why we must have knowledge about how to write PySpark DataFrame to CSV file.
Since PySpark 2.0 version, CSV is natively supported in PySpark without using any other external dependencies.
Let’s first create a PySpark DataFrame in order to write it into a CSV file.
Headings of Contents
Creating PySpark DataFrame
To create PySpark DataFrame, PySpark provides a Spark session that has some properties and methods to create PySpark DataFrame.
Spark session is the entry point of any spark application and it has the capability to create spark DataFrame, Execute SQL ( Structure Query Language ) over the PySpark DataFrame, Cache table, etc.
PySpark session has an attribute called builder which is an instance of the PySpark Builder class it also has some methods like appName() and getOrCreate() and this method is used to create spark session.
PySpark Program to Create DataFrame:
from pyspark.sql import SparkSession
data = [
("Pankaj", "Kumar", "Developer", "IT", 33000),
("Hari", "Sharma", "Developer", "IT", 40000),
("Anshika", "Kumari", "HR Executive", "HR", 25000),
("Shantnu", "Saini", "Manual Tester", "IT", 25000),
("Avantika", "Srivastava", "Senior HR Manager", "HR", 45000),
("Jay", "Kumar", "Junior Accountant", "Account", 23000),
("Vinay", "Singh", "Senior Accountant", "Account", 40000),
]
columns = ["first_name", "last_name", "designation", "department", "salary"]
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# creating dataframe
df = spark.createDataFrame(data, columns)
# displaying DataFrame
df.show(truncate=False)
Output
+----------+----------+-----------------+----------+------+
|first_name|last_name |designation |department|salary|
+----------+----------+-----------------+----------+------+
|Pankaj |Kumar |Developer |IT |33000 |
|Hari |Sharma |Developer |IT |40000 |
|Anshika |Kumari |HR Executive |HR |25000 |
|Shantnu |Saini |Manual Tester |IT |25000 |
|Avantika |Srivastava|Senior HR Manager|HR |45000 |
|Jay |Kumar |Junior Accountant|Account |23000 |
|Vinay |Singh |Senior Accountant|Account |40000 |
+----------+----------+-----------------+----------+------+Explanation of the above code:
- First, I imported the SparkSession class from pyspark.sql to create the spark session.
- Defined the list of tuples and each tuple has information about the employee.
- Defined the list that has DataFrame column names.
- Created the spark session using builder attribute and appName() and getOrCreate() methods.
- Created the PySpark DataFrame using the spark session createDataFrame() method.
- And finally displayed the data frame using the show() method.
Now let’s see how can we convert PySpark DataFrame to CSV ( Command Separated Value ) file format.
Write PySpark DataFrame to CSV (Comma Separated Value)
PySpark DataFrame has a write attribute that returns instances of the PySpark DataFrameWrite class and DataFrameWriter class has a csv() method That is used to convert PySpark DataFrame to CSV. The csv() method accepts multiple parameters to write DataFrame to a CSV file.
The first question comes to mind, before converting DataFrame to CSV, why do we need to convert PySpark DataFrame to CSV?
let me take an example so that I can explain it in a better way.
I am going to take a simple example. Suppose we have a source data of employees which contains some information about the employees like first_name, last_name, age, salary, gender, and some other information and we want to perform some transformations ( Changes based on the requirement ) on top of that source data and finally save latest data to another CSV file or maybe another target location, In that scenario, we need to convert PySpark DataFrame to CSV.
There are various options also available to write PySpark data frames to CSV files. To use options we have to use the option() and options() methods of DataFrameWriter class.
For example: In the above PySpark DataFrame, I want to add a new column called full_name and the full_name column will be a combination of the first_name and last_name columns Then I want to write the latest PySpark DataFrame to a CSV file.
To concatenate the value of the first_name and last_name columns, I have used the built-in function called concat_ws().The concat_ws() function takes the separator as the first parameter and other parameters represent the values to be concatenated.
PySpark Code to concatenate the value of first_name and last_name:
from pyspark.sql import SparkSession
from pyspark.sql.functions import concat_ws
data = [
("Pankaj", "Kumar", "Developer", "IT", 33000),
("Hari", "Sharma", "Developer", "IT", 40000),
("Anshika", "Kumari", "HR Executive", "HR", 25000),
("Shantnu", "Saini", "Manual Tester", "IT", 25000),
("Avantika", "Srivastava", "Senior HR Manager", "HR", 45000),
("Jay", "Kumar", "Junior Accountant", "Account", 23000),
("Vinay", "Singh", "Senior Accountant", "Account", 40000),
]
columns = ["first_name", "last_name", "designation", "department", "salary"]
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# creating dataframe
df = spark.createDataFrame(data, columns)
# transformation
new_df = df.withColumn("full_name", concat_ws(' ', df.first_name, df.last_name))
# displaying
new_df.show(truncate=False)
The latest PySpark DataFrame will be like this.
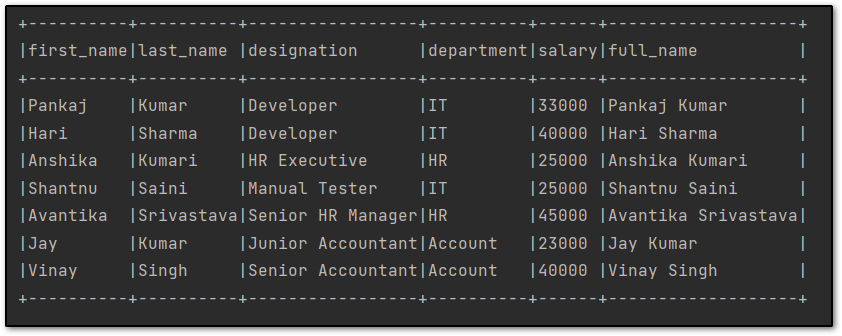
After performing transformations on top of PySpark DataFrame, You can convert the PySpark data frame to a CSV file.
Use the write property of the DataFrame to write the DataFrame to a CSV file. The write property returns the instance of the PySpark DataFrameWriter class.
The DataFrameWriter class has various methods, csv() method is one of them which takes various parameters in order to save or write PySpark DataFrame at a specified location on the machine, The first parameter always represents the location where you want to write DataFrame.
Syntax of the csv() method:
csv(path: str, mode: Optional[str] = None, compression: Optional[str] = None, sep: Optional[str] = None, quote: Optional[str] = None, escape: Optional[str] = None, header: Union[bool, str, None] = None, nullValue: Optional[str] = None, escapeQuotes: Union[bool, str, None] = None, quoteAll: Union[bool, str, None] = None, dateFormat: Optional[str] = None, timestampFormat: Optional[str] = None, ignoreLeadingWhiteSpace: Union[bool, str, None] = None, ignoreTrailingWhiteSpace: Union[bool, str, None] = None, charToEscapeQuoteEscaping: Optional[str] = None, encoding: Optional[str] = None, emptyValue: Optional[str] = None, lineSep: Optional[str] = None)
Let’s convert PySpark DataFrame to CSV using only one parameter.
new_df.write.csv("new_employee")
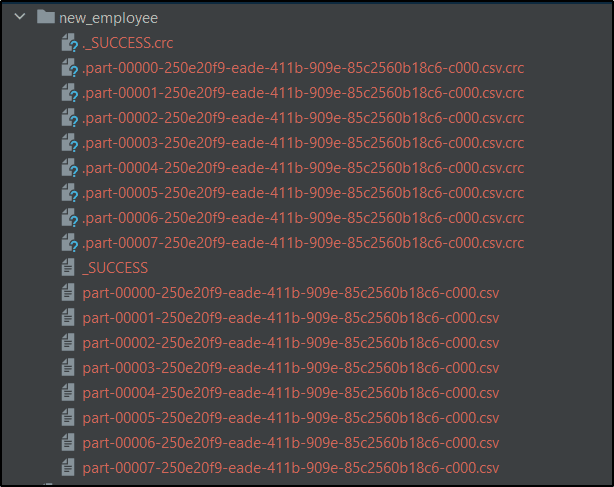
Note:- The above csv() method will create a folder called new_employee and inside new_employee directory it will write multiple part of the PySpark DataFrame.Each file will have extension with same method that you have applied like .csv(), .json(), .txt() etc. It also creates some other files except part files.Each .csv file will contains some rows of the PySpark DataFrame.
You can see my new_employee directory along with multiple files.
Write PySpark DataFrame to CSV with Header
In most of the CSV files, the first row represents the column name, therefore, we have to set header=True in csv() method so that the CSV file can store PySpark column names as the first parameter.
new_df.write.csv("new_employee", header=True)
Write PySpark DataFrame to CSV with Delimeter
Pyspark write property has a method called option() that is used to provide extra options to save DataFrame to CSV. The delimiter of the option() method is used to specify the delimiter of the CSV file.
A delimiter is a character that is used to separate the values in a CSV file. In the below command, I have used a comma as a delimiter.
new_df.write.option("delimiter", ",").csv("new_employee")
Write PySpark DataFrame to CSV with saving modes:
PySpark DataFrameWriter class also has a method called mode(). The mode() method is used to specify the saving model of the PySpark DataFrame.
To specify we have to use the mode() method and pass the mode name inside it.
There are four types of modes available in the mode() method.
| Saving Mode Name | Description |
|---|---|
| overwrite | It overwrites the content of the file. |
| append | It appends the data to an existing file. |
| ignore | It ignores the PySpark write operation when the file already exists. |
| error | It returns an error when the file already exists. This is the default option. |
Example:
new_df.write.option("delimiter", ",").mode("overwrite").csv("new_employee")
Write PySpark DataFrame into a Single CSV File:
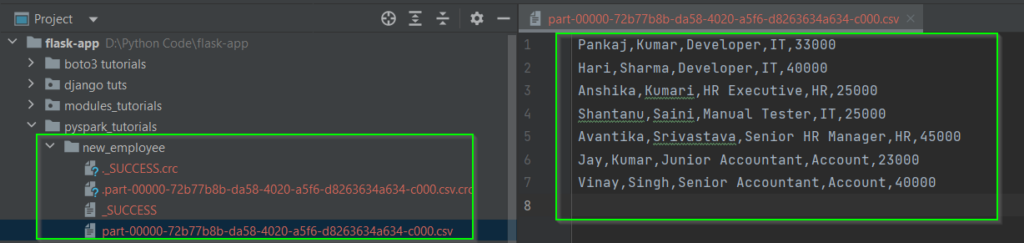
In the above approach, The csv() method will create a folder and write PySpark DataFrame inside it in multiple files. But in real life, we want to write PySpark DataFrame into a single CSV file. To do that, we have to use coalesce() method to reduce the number of partitions to 1 and then write it into a CSV file.
new_df.coalesce(1).write.option("delimiter", ",").mode("overwrite").csv("new_employee", header=True)
After executing the above code, the Directory structure will be like this.
PySpark DataFrame into CSV:
first_name,last_name,designation,department,salary,full_name
Pankaj,Kumar,Developer,IT,33000,Pankaj Kumar
Hari,Sharma,Developer,IT,40000,Hari Sharma
Anshika,Kumari,HR Executive,HR,25000,Anshika Kumari
Shantnu,Saini,Manual Tester,IT,25000,Shantnu Saini
Avantika,Srivastava,Senior HR Manager,HR,45000,Avantika Srivastava
Jay,Kumar,Junior Accountant,Account,23000,Jay Kumar
Vinay,Singh,Senior Accountant,Account,40000,Vinay SinghComplete Source Code
You can get the complete source code to write PySpark DataFrame to a CSV file.
from pyspark.sql import SparkSession
from pyspark.sql.functions import concat_ws
data = [
("Pankaj", "Kumar", "Developer", "IT", 33000),
("Hari", "Sharma", "Developer", "IT", 40000),
("Anshika", "Kumari", "HR Executive", "HR", 25000),
("Shantanu", "Saini", "Manual Tester", "IT", 25000),
("Avantika", "Srivastava", "Senior HR Manager", "HR", 45000),
("Jay", "Kumar", "Junior Accountant", "Account", 23000),
("Vinay", "Singh", "Senior Accountant", "Account", 40000),
]
columns = ["first_name", "last_name", "designation", "department", "salary"]
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# creating dataframe
df = spark.createDataFrame(data, columns)
# transformation
new_df = df.withColumn("full_name", concat_ws(' ', df.first_name, df.last_name))
# displaying dataframe
new_df.show(truncate=True)
# # write pyspark dataframe into multiple csv file
new_df.write.option("delimiter", ",").mode("overwrite").csv("new_employee")
# write pyspark dataframe into single csv file
new_df.coalesce(1).write.option("delimiter", ",").mode("overwrite").csv("new_employee", header=True)
Write PySpark DataFrame into CSV PDF File
I have organized all the source code into a PDF file format in a very crisp way so that you can download it and keep it for further use cases.
PySpark Other Articles:
- How to convert PySpark Row To Dictionary
- PySpark Column Class with Examples
- PySpark Sort Function with Examples
- How to read CSV files using PySpark
- PySpark col() Function with Examples
- Convert PySpark DataFrame Column to List
Conclusion
Throughout this article, we have seen all about how to write PySpark DataFrame to CSV file using the DataFrameWriter’s csv() method.
There are multiple parameters accepted by csv() method and except csv() method, you can use options() or option() and mode() method to provide extra properties of PySpark DataFrame.
You can any number of parameters or options as per your requirement. You have remembered one thing to write the PySpark data frame into a single CSV file you have to use coalesce() and repartitions() methods.
If you like this article, please share and keep visiting for further interesting informational PySpark tutorials.
Thanks for taking the time to read this article.
have a nice day…





